Rozmowy między LLM-ami mogą zautomatyzować tworzenie exploitów, pokazuje badanie.
19 lipca 2025 funkcja
autorstwa Ingrid Fadelli, Phys.org
autor współpracujący
redakcja Gaby Clark, recenzja Andrew Zinina
redaktor naukowy
redaktor prowadzący
Ten artykuł został zrecenzowany zgodnie z procesem redakcyjnym i zasadami działania Science X. Redaktorzy zaznaczyli następujące cechy, dbając o wiarygodność treści:
zweryfikowane
godne zaufania źródło
skorygowane
Ze wzrostem złożoności komputerów i oprogramowania hackera muszą szybko adaptować się do najnowszych osiągnięć i opracowywać nowe strategie planowania i przeprowadzania cyberataków. Jedną z powszechnych strategii złośliwego przenikania do systemów komputerowych jest znana jako wykorzystanie oprogramowania.
Jak sugeruje nazwa, ta strategia polega na wykorzystywaniu błędów, luk lub wad w oprogramowaniu do wykonania nieautoryzowanych działań. Działania te obejmują uzyskanie dostępu do kont osobistych użytkownika lub komputera, zdalne wykonanie złośliwego oprogramowania lub określonych poleceń, kradzież lub modyfikację danych użytkownika oraz zawieszenie programu lub systemu.
Zrozumienie, w jaki sposób hakerzy opracowują potencjalne luki i planują ataki, jest sprawą najwyższej ważności, ponieważ ostatecznie może pomóc w opracowaniu skutecznych środków bezpieczeństwa przeciwko ich atakom. Dotychczas tworzenie luk było możliwe głównie dla osób posiadających szeroką wiedzę z zakresu programowania, protokołów regulujących wymianę danych między urządzeniami lub systemami oraz systemów operacyjnych.
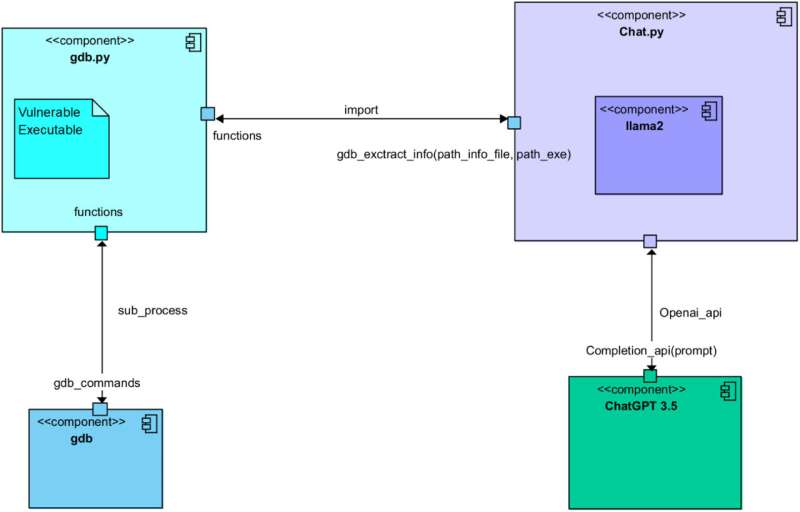
Niedawny artykuł opublikowany w czasopiśmie Computer Networks, jednak pokazuje, że taka konieczność może już nie istnieć. Ataki mogłyby być również automatycznie generowane poprzez wykorzystanie wielkich modeli językowych (LLM), takich jak model stanowiący podstawę znanego platformy konwersacyjnej ChatGPT. Tak właśnie autorzy artykułu byli w stanie zautomatyzować generowanie ataków poprzez odpowiednio prowokującą rozmowę między ChatGPT a Llama 2, otwartym źródłem LLM opracowanym przez Meta.
'Pracujemy w dziedzinie cyberbezpieczeństwa, z podejściem atakującym,' powiedział Tech Xplore Simon Pietro Romano, współautor artykułu. 'Zależało nam na zrozumieniu, jak daleko możemy zajść, wykorzystując LLM do ułatwienia działań badawczych dotyczących penetracji.'
W ramach swoich ostatnich badań Romano i jego koledzy rozpoczęli rozmowę mającą na celu generowanie ataków oprogramowania między ChatGPT a Llama 2. Poprzez staranne opracowanie prowokacji podawanych obu modelom, zapewnili, że modele przyjęły różne role i wykonały pięć różnych kroków znanych z wspierania tworzenia ataków.
Te kroki obejmowały: analizę programu podatnego, identyfikację potencjalnych luk, planowanie ataku opartego na tych lukach, zrozumienie zachowania ukierunkowanych systemów sprzętowych i ostateczne wygenerowanie faktycznego kodu ataku.
'Pozwoliliśmy dwóm różnym LLM na współpracę, aby przejść przez wszystkie kroki zaangażowane w proces tworzenia prawidłowego ataku na podatny program,' wyjaśnił Romano. 'Jeden z dwóch LLM zbiera 'kontekstowe' informacje o podatnym programie i jego konfiguracji w czasie działania. Następnie prosi drugiego LLM o stworzenie działającego ataku. W skrócie, pierwszy LLM jest dobry w zadawaniu pytań. Drugi jest dobry w pisaniu (kodu) ataku.'
Dotychczas badacze przetestowali swoją opartą na LLM metodę generowania ataków tylko w eksperymencie wstępnym. Niemniej jednak stwierdzili, że ostatecznie wygenerowała ona w pełni funkcjonalny kod dla ataku przepełnienia bufora, czyli ataku polegającego na nadpisaniu danych przechowywanych przez system w celu zmiany zachowania konkretnych programów.
'To jest badanie wstępne, ale jasno dowodzi możliwości tego podejścia,' powiedział Romano. 'Implikacje dotyczą możliwości uzyskania w pełni zautomatyzowanych testów penetracyjnych i oceny podatności (VAPT).'
Niedawne badanie Romano i jego kolegów stawia ważne pytania dotyczące ryzyk związanych z LLM, ponieważ pokazuje, jak hakerzy mogliby je wykorzystać do automatyzacji generowania ataków. W swoich kolejnych badaniach naukowcy planują kontynuować badania nad skutecznością opracowanej strategii generowania ataków, aby wesprzeć przyszły rozwój LLM, a także postęp w środkach bezpieczeństwa cybernetycznego.
'Obecnie eksplorujemy dalsze obszary badań w tej samej dziedzinie zastosowań,' dodał Romano. 'Mianowicie, czujemy, że naturalne kontynuacje naszych badań wpisują się w obszar tzw. podejścia 'agentic', będącego minimalnie nadzorowane przez człowieka.'
Napisane dla Ciebie przez naszą autorkę Ingrid Fadelli, edytowane przez Gabę Clarka, a sprawdzone i zrecenzowane przez Andrew Zinina - ten artykuł jest wynikiem starannej pracy ludzkiej. Polegamy na czytelnikach takich jak Ty, aby utrzymać niezależną dziennikarstwo naukowe przy życiu. Jeśli ta relacja ma dla Ciebie znaczenie, rozważ wsparcie finansowe (szczególnie miesięczne). Otrzymasz bezreklamowe konto jako podziękowanie. Więcej informacji: Rozmowa między Llamą 2 i ChatGPT w celu automatycznego tworzenia exploitów. Sieci komputerowe (2025). DOI: 10.1016/j.comnet.2025.111501. © 2025 Science X Network


