Gesprekken tussen LLM's zouden volgens een onderzoek de creatie van exploits kunnen automatiseren.
19 juli 2025 functie
door Ingrid Fadelli, Phys.org
medewerker
bewerkt door Gaby Clark, beoordeeld door Andrew Zinin
wetenschappelijk redacteur
hoofdredacteur
Dit artikel is beoordeeld volgens het redactionele proces en het beleid van Science X. Redacteuren hebben de volgende kenmerken benadrukt terwijl ze de geloofwaardigheid van de inhoud waarborgden:
feiten gecontroleerd
betrouwbare bron
nagekeken op fouten
Naarmate computers en software steeds geavanceerder worden, moeten hackers zich snel aanpassen aan de nieuwste ontwikkelingen en nieuwe strategieën bedenken om cyberaanvallen te plannen en uit te voeren. Een veelvoorkomende strategie om kwaadaardig computer systemen binnen te dringen staat bekend als software-exploitatie.
Zoals de naam al aangeeft houdt deze strategie de exploitatie van bugs, kwetsbaarheden of fouten in software in om ongeautoriseerde acties uit te voeren. Deze acties omvatten het verkrijgen van toegang tot persoonlijke accounts of computers van een gebruiker, het op afstand uitvoeren van malware of specifieke opdrachten, het stelen of wijzigen van gegevens van een gebruiker of het laten crashen van een programma of systeem.
Het begrijpen van hoe hackers mogelijke exploits bedenken en hun aanvallen plannen is van het grootste belang, aangezien het uiteindelijk kan helpen om effectieve beveiligingsmaatregelen tegen hun aanvallen te ontwikkelen. Tot nu toe was het maken van exploits voornamelijk mogelijk voor personen met uitgebreide kennis van programmeren, de protocollen die de uitwisseling van gegevens tussen apparaten of systemen regelen, en besturingssystemen.
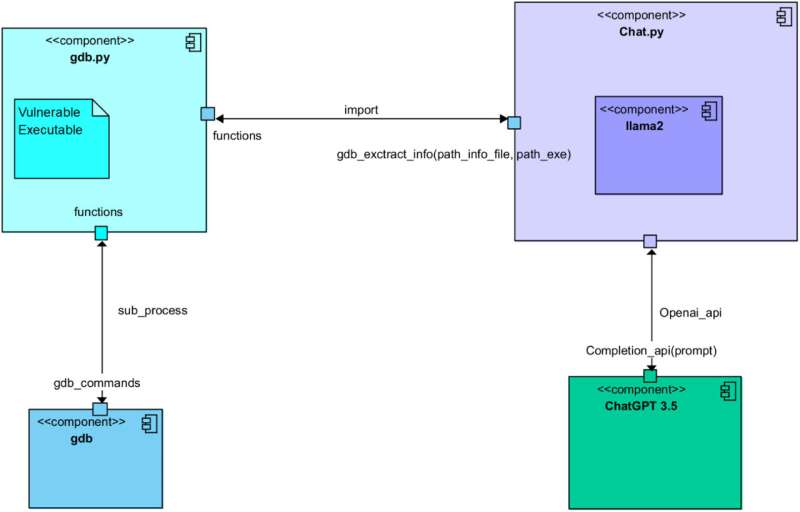
Een recent artikel gepubliceerd in Computer Networks laat echter zien dat dit misschien niet langer het geval is. Exploits zouden ook automatisch gegenereerd kunnen worden door gebruik te maken van grote taalmodellen (LLM's), zoals het model dat ten grondslag ligt aan het bekende conversatieplatform ChatGPT. De auteurs van het artikel slaagden er zelfs in om de generatie van exploits te automatiseren via een zorgvuldig gestelde conversatie tussen ChatGPT en Llama 2, de open-source LLM ontwikkeld door Meta.
'We werken op het gebied van cybersecurity, met een offensieve aanpak,' zei Simon Pietro Romano, mede-senior auteur van het artikel, tegen Tech Xplore. 'We waren geïnteresseerd in het begrijpen van hoever we konden gaan met het gebruik van LLM's om penetratietestactiviteiten te vergemakkelijken.'
Als onderdeel van hun recente studie initieerden Romano en zijn collega's een gesprek met als doel software exploits te genereren tussen ChatGPT en Llama 2. Door de prompts die ze aan de twee modellen voerden zorgvuldig te manipuleren, zorgden ze ervoor dat de modellen verschillende rollen op zich namen en vijf verschillende stappen voltooiden die bekend staan om de creatie van exploits te ondersteunen.
Deze stappen omvatten: de analyse van een kwetsbaar programma, het identificeren van mogelijke exploits, het plannen van een aanval op basis van deze exploits, het begrijpen van het gedrag van gerichte hardware systemen en uiteindelijk het genereren van de daadwerkelijke exploitcode.
'We lieten twee verschillende LLM's met elkaar interacteren om door al de stappen die betrokken zijn bij het proces van het maken van een geldige exploit voor een kwetsbaar programma te komen,' legde Romano uit. 'Een van de twee LLM's verzamelt 'contextuele' informatie over het kwetsbare programma en zijn runtime-configuratie. Vervolgens vraagt het de andere LLM om een werkende exploit te maken. Kort gezegd is de eerste LLM goed in het stellen van vragen. De laatste is goed in het schrijven (exploit) van code.'
Tot nu toe hebben de onderzoekers hun op LLM gebaseerde methode voor exploitgeneratie alleen getest in een eerste experiment. Desalniettemin ontdekten ze dat het uiteindelijk volledig functionele code produceerde voor een buffer overflow exploit, een aanval waarbij gegevens die zijn opgeslagen door een systeem worden overschreven om het gedrag van specifieke programma's te veranderen.
'Dit is een voorlopige studie, maar het bewijst duidelijk de haalbaarheid van de aanpak,' zei Romano. 'De implicaties betreffen de mogelijkheid om volledig geautomatiseerde Penetration Testing en Vulnerability Assessment (VAPT) te bereiken.'
De recente studie van Romano en zijn collega's roept belangrijke vragen op over de risico's van LLM's, aangezien het laat zien hoe hackers ze kunnen gebruiken om de generatie van exploits te automatiseren. In hun volgende studies zijn de onderzoekers van plan om door te gaan met het onderzoeken van de effectiviteit van de door hen bedachte exploitgeneratiestrategie om de toekomstige ontwikkeling van LLM's, evenals de vooruitgang van beveiligingsmaatregelen, te informeren.
'We verkennen nu verdere onderzoeksgebieden in hetzelfde toepassingsgebied,' voegde Romano toe. 'Namelijk, we hebben het gevoel dat de natuurlijke voortzetting van ons onderzoek ligt in het gebied van de zogenaamde 'agentic' benadering, met minimale menselijke supervisie.'
Geschreven voor jou door onze auteur Ingrid Fadelli, bewerkt door Gaby Clark, en gecontroleerd en beoordeeld door Andrew Zinin - dit artikel is het resultaat van nauwkeurig menselijk werk. We vertrouwen op lezers zoals jij om onafhankelijke wetenschapsjournalistiek in leven te houden. Als deze berichtgeving belangrijk voor je is, overweeg dan een donatie (vooral maandelijks). Je krijgt een advertentievrij account als dank je wel.
Meer informatie: Een praatje tussen Llama 2 en ChatGPT voor de geautomatiseerde creatie van exploits. Computernetwerken (2025). DOI: 10.1016/j.comnet.2025.111501.
© 2025 Science X Network



