Test di un modello di apprendimento approfondito non supervisionato per l'imitazione da parte di un robot dei movimenti umani
10 marzo 2024 Caratteristica
Questo articolo è stato esaminato secondo il processo editoriale e le politiche di Science X. Gli editori hanno evidenziato i seguenti attributi garantendo la credibilità del contenuto:
- verifica dei fatti
- preprint
- fonte affidabile
- corretto
di Ingrid Fadelli, Tech Xplore
I robot che possono imitare da vicino le azioni e i movimenti degli esseri umani in tempo reale potrebbero essere incredibilmente utili, poiché potrebbero imparare a completare compiti quotidiani in modi specifici senza dover essere ampiamente pre-programmati su questi compiti. Mentre le tecniche per consentire l'apprendimento per imitazione sono migliorate notevolmente negli ultimi anni, le loro prestazioni sono spesso ostacolate dalla mancanza di corrispondenza tra il corpo di un robot e quello del suo utente umano.
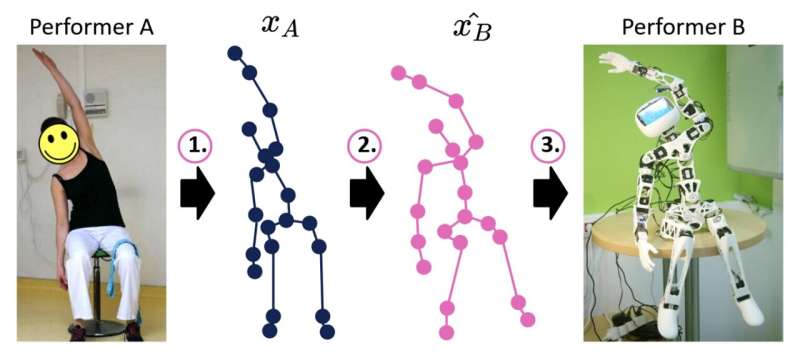
I ricercatori di U2IS, ENSTA Paris hanno recentemente introdotto un nuovo modello basato sull'apprendimento profondo che potrebbe migliorare le capacità di imitazione del movimento dei sistemi robotici umanoidi. Questo modello, presentato in un articolo pre-pubblicato su arXiv, affronta l'imitazione del movimento in tre passaggi distinti, progettati per ridurre i problemi di corrispondenza tra umano e robot segnalati in passato.
'Questo lavoro di ricerca in fase iniziale mira a migliorare l'imitazione umano-robot online traducendo sequenze di posizioni articolari dal dominio dei movimenti umani a un dominio di movimenti realizzabili da un determinato robot, quindi vincolati dalla sua incarnazione,' hanno scritto Louis Annabi, Ziqi Ma e Sao Mai Nguyen nel loro articolo. 'Sfruttando le capacità di generalizzazione dei metodi di apprendimento profondo, affrontiamo questo problema proponendo un modello di rete neurale codificatore-decodificatore che esegue una traduzione di dominio in dominio.'
Il modello sviluppato da Annabi, Ma e Nguyen suddivide il processo di imitazione umano-robot in tre fasi chiave, ovvero stima della posa, riallineamento del movimento e controllo del robot. In primo luogo, utilizza algoritmi di stima della posa per prevedere le sequenze di posizioni articolari a scheletro che sottendono i movimenti dimostrati dagli agenti umani.
Successivamente, il modello traduce questa sequenza prevista di posizioni articolari a scheletro in posizioni articolari simili che possono essere realisticamente prodotte dal corpo del robot. Infine, queste sequenze tradotte vengono utilizzate per pianificare i movimenti del robot, teoricamente comportando movimenti dinamici che potrebbero aiutare il robot nell'esecuzione del compito a portata di mano.
'Per addestrare un tale modello, si potrebbero utilizzare coppie di movimenti robotici e umani associati, [tuttavia] tali dati accoppiati sono estremamente rari nella pratica e noiosi da raccogliere,' hanno scritto i ricercatori nel loro articolo. 'Pertanto, ci rivolgiamo ai metodi di apprendimento profondo per traduzioni tra domini non accoppiati, che adattiamo per eseguire l'imitazione umano-robot.'
Annabi, Ma e Nguyen hanno valutato le prestazioni del loro modello in una serie di test preliminari, confrontandolo con un metodo più semplice per riprodurre le orientazioni articolari che non si basa sull'apprendimento profondo. Il loro modello non ha ottenuto i risultati sperati, suggerendo che attuali metodi di apprendimento profondo potrebbero non essere in grado di riallineare con successo i movimenti in tempo reale.
I ricercatori hanno ora in programma di condurre ulteriori esperimenti per identificare eventuali problemi con il loro approccio, in modo da poterli affrontare e adattare il modello per migliorarne le prestazioni. I risultati finora del team suggeriscono che sebbene le tecniche di apprendimento profondo non supervisionato possano essere utilizzate per abilitare l'imitazione nell'apprendimento dei robot, le loro prestazioni non sono ancora sufficientemente buone da poter essere impiegate su robot reali.
'Il lavoro futuro estenderà lo studio attuale in tre direzioni: Investigare ulteriormente il fallimento del metodo attuale, come spiegato nell'ultima sezione, creare un set di dati di movimento accoppiato da imitazione uomo-uomo o uomo-robot, e migliorare l'architettura del modello per ottenere previsioni di riallineamento più accurate,' concludono i ricercatori nel loro articolo.
© 2024 Science X Network



