Test d'un modèle d'apprentissage profond non supervisé pour l'imitation de mouvements humains par un robot
Article du 10 mars 2024
L'article suivant a fait l'objet d'un examen approfondi basé sur des protocoles et des méthodes conçus par l'équipe éditoriale de Science X. Les points de crédibilité validés par les éditeurs comprennent :
- faits vérifiés
- préimpression
- source fiable
- relire
Rédigé par Ingrid Fadelli, Tech Xplore
Les robots imitant l’humain pourraient révolutionner nos vies s’ils pouvaient apprendre à exécuter les tâches quotidiennes avec précision sans préprogrammation approfondie. Malgré des progrès significatifs dans la technologie de l'apprentissage par imitation, l'obstacle de l'incohérence entre les caractéristiques physiques d'un robot et celles d'un humain demeure.
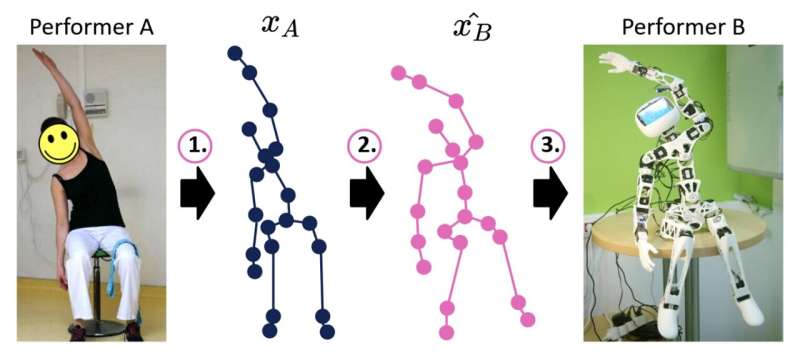
Modèle basé sur l'apprentissage profond développé par l'U2IS, les chercheurs de l'ENSTA Paris s'efforcent d'améliorer les capacités d'imitation de mouvement des robots humanoïdes. Ce modèle, actuellement en phase de pré-publiation sur arXiv, aborde le problème en traitant l'imitation de mouvement comme un processus en trois étapes, atténuant ainsi le problème de correspondance homme-robot.
"Nos recherches préliminaires visent à faire progresser l'imitation homme-robot en ligne en traduisant des séquences de positions articulaires depuis les mouvements humains vers celles réalisables par un robot particulier, en tenant compte de ses contraintes physiques", ont expliqué Louis Annabi, Ziqi Ma et Sao Mai Nguyen dans leur étude. papier. «Nous proposons un modèle de réseau neuronal codeur-décodeur effectuant une traduction de domaine à domaine qui exploite les capacités de généralisation des méthodes d'apprentissage en profondeur.»
Le modèle d'Annabi, Ma et Nguyen décompose le processus d'imitation homme-robot en trois étapes principales : l'estimation de la pose, le reciblage de mouvement et le contrôle du robot. Cela commence par utiliser des algorithmes d’estimation de pose pour prédire les séquences de positions des articulations du squelette telles que présentées par les humains.
Ensuite, le modèle traduit les séquences prévues de positions squelette-articulations en positions articulaires similaires réalisables par le robot. Ces séquences sont ensuite utilisées pour guider les mouvements du robot, lui permettant potentiellement d'effectuer la tâche souhaitée.
«La formation d'un tel modèle impliquerait idéalement des paires de mouvements associés du robot et de l'humain. Cependant, ces données sont difficiles à trouver et leur collecte est un processus fastidieux. Par conséquent, nous nous sommes tournés vers la traduction non appariée de domaine à domaine en utilisant des méthodes d'apprentissage profond pour l'imitation homme-robot", ont mentionné les chercheurs.
Lors de leurs tests préliminaires, Annabi, Ma et Nguyen ont évalué leur modèle par rapport à une méthode simple qui ne repose pas sur l'apprentissage en profondeur pour reproduire des orientations communes. Les résultats n'ont pas répondu à leurs attentes, ce qui suggère que les techniques d'apprentissage en profondeur existantes pourraient être inadéquates pour recibler les mouvements en temps réel.
L'équipe prévoit d'effectuer davantage de tests pour détecter toute limitation avant d'apporter les ajustements nécessaires au modèle. Les résultats obtenus jusqu’à présent indiquent que même si des techniques d’apprentissage profond non supervisé peuvent être appliquées pour permettre un apprentissage par imitation dans les robots, elles n’ont pas encore atteint un niveau de performance adapté à une utilisation sur des robots réels.
«Notre travail futur est triple : approfondir l'échec de la méthode actuelle, construire une base de données de données de mouvement appariées obtenues soit à partir d'une imitation humain-humain ou robot-humain, et améliorer la structure du modèle pour fournir des prédictions de reciblage précises, ", ont conclu les chercheurs.
Pour plus de détails : reportez-vous aux travaux de Louis Annabi et de son équipe intitulés "Unsupervised Motion Retargeting for Human-Robot Imitation".
© 2024 Réseau Science X



