Un nuovo approccio per la densificazione delle mappe nel riconoscimento visuale dei luoghi
22 maggio 2023 feature
Questo articolo è stato revisionato secondo il processo editoriale e le politiche di Science X. Gli editor hanno evidenziato i seguenti attributi garantendo la credibilità del contenuto:
- fact-checked
- pubblicazione peer-reviewed
- fonte affidabile
- corretta la bozza
di Ingrid Fadelli, Tech Xplore
Il riconoscimento visuale dei luoghi (VPR) è il compito di identificare la posizione nella quale sono state scattate immagini specifiche. Gli scienziati informatici hanno recentemente sviluppato vari algoritmi di deep learning che possono affrontare efficacemente questo compito, permettendo agli utenti di sapere in quale luogo noto è stata catturata un'immagine.
Un team di ricercatori presso l'Università Tecnologica di Delft (TU Delft) ha recentemente introdotto un nuovo approccio per migliorare le prestazioni degli algoritmi di deep learning per le applicazioni VPR. Il loro metodo proposto, descritto in un articolo su IEEE Transactions on Robotics, si basa su un nuovo modello chiamato regressione continua del descrittore del luogo (CoPR).
"Il nostro studio è stato messo in discussione sui fondamentali vincoli delle prestazioni VPR e sui relativi approcci di localizzazione visuale", ha detto Mubariz Zaffar, primo autore dello studio, a Tech Xplore.
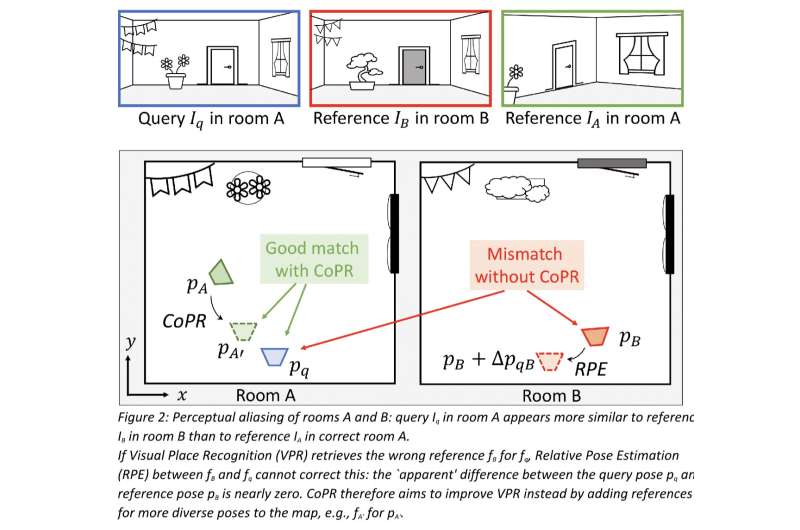
"Innanzitutto, abbiamo parlato del problema dell'''aliasing percettivo'', ovvero aree distintive con apparenze visive simili. Come esempio semplice, immaginiamo che raccogliamo immagini di riferimento di un veicolo che guida sulla corsia più a destra di un'autostrada. Se successivamente guidiamo sulla corsia più a sinistra della stessa autostrada, la stima VPR più accurata sarebbe quella di abbinare queste immagini di riferimento vicine. Tuttavia, il contenuto visivo potrebbe corrispondere erroneamente a una diversa sezione dell'autostrada dove sono state anche raccolte immagini di riferimento sulla corsia più a sinistra."
Un modo possibile per superare questa limitazione degli approcci di VPR identificati da Zaffar e dai suoi colleghi potrebbe essere quello di addestrare l'estrattore di descrittori di immagini (ovvero un componente dei modelli VPR che estrae elementi descrittivi dalle immagini) per analizzare le immagini in modo simile indipendentemente dalla corsia di guida in cui sono state scattate. Tuttavia, questo ridurrebbe la loro capacità di determinare efficacemente il luogo in cui è stata scattata un'immagine.
"Abbiamo quindi chiesto a noi stessi: è VPR possibile solo se raccogliamo immagini in tutte le corsie per ogni autostrada mappata o se guidiamo solo nella stessa corsia esatta? Abbiamo voluto estendere il paradigma di recupero immagini semplice ma efficace di VPR per gestire tali problemi pratici", ha detto Zaffar.
"In secondo luogo, ci siamo resi conto che anche la stima di posa di un sistema VPR perfetto sarebbe limitata in precisione, poiché la dimensione finita delle immagini di riferimento e le loro posizioni significavano che la mappa non può contenere un riferimento con la stessa posa per ogni possibile interrogazione. Abbiamo quindi considerato che potrebbe essere più importante affrontare questa scarsità anziché cercare di costruire descrittori VPR ancora migliori."
Revisando la letteratura precedente, Zaffar e i suoi colleghi si sono anche resi conto che i modelli VPR sono spesso utilizzati come parte di un sistema più ampio. Ad esempio, le tecniche di mappatura e localizzazione simultanea visuale (SLAM) possono beneficiare degli approcci VPR per rilevare i cosiddetti chiusure di loop, mentre gli approcci di localizzazione grossolana-fine possono raggiungere una precisione di localizzazione sub-metrica raffinando le stime di posa grossolane di VPR.
"Rispetto a questi sistemi più complessi, il passaggio VPR si adatta bene a ambienti ampi ed è facile da implementare, ma la sua stima di posa non è così precisa, in quanto può solo restituire la posa o le pose dell'immagine o delle immagini viste in precedenza che corrispondono visivamente al richiamo", ha detto Zaffar.
"Tuttavia, SLAM e la stima della posa relativa forniscono stime di posa altamente accurate utilizzando le stesse immagini e posizioni di riferimento sparse, quindi in cosa sono diversi questi approcci da VPR? La nostra osservazione è che tali tecniche costruiscono una rappresentazione spaziale continua dalle referenze che collega esplicitamente una posa alle caratteristiche visive, permettendo di ragionare sul contenuto visivo alle posizioni interpolate ed estrapolate dalle referenze date."
Basandosi sulle loro osservazioni, i ricercatori hanno deciso di esplorare se le stesse rappresentazioni continue raggiunte dagli approcci di mappatura e stima della posa relativa di SLAM potessero essere estese ai modelli VPR che operano da soli. Gli approcci VPR convenzionali funzionano convertendo un'immagine di query in un singolo vettore di descrittore cosiddetto e quindi confrontandolo con i descrittori precomputati della mappa. Collettivamente, tutti questi descrittori di riferimento sono indicati come "mappa".
Dopo aver confrontato questi descrittori, il modello determina quale descrittore di riferimento corrisponde più da vicino al descrittore dell'immagine di query. Il modello risolve quindi il compito di VPR condividendo la posizione e l'orientamento (cioè la posa) del descrittore di riferimento che è più simile al descrittore dell'immagine di query.
Per migliorare la localizzazione di VPR, Zaffar e i suoi colleghi hanno semplicemente densificato l'intera "mappa" dei descrittori utilizzando modelli di deep learning. Invece di considerare i descrittori delle immagini di riferimento come un insieme discreto separato dalle loro pose, il loro metodo considera essenzialmente i riferimenti come punti su una funzione continua sottostante che mette in relazione le pose con i loro descrittori.
"Se si considera una coppia di riferimenti con due pose vicine (quindi, immagini con posizioni e orientamenti leggermente diversi, ma che guardano comunque la stessa scena), si può immaginare che i descrittori siano relativamente simili poiché rappresentano contenuti visivi simili", ha spiegato Julian Kooij, co-autore della ricerca.
"Tuttavia, sono anche leggermente diversi poiché rappresentano punti di vista diversi. Sebbene sarebbe difficile definire manualmente come cambiano esattamente i descrittori, questo può essere appreso dai descrittori di riferimento scarsamente disponibili con le pose note. Questa è quindi l'essenza del nostro approccio: possiamo modellare come i descrittori delle immagini cambiano in funzione di una variazione della posa e usarlo per densificare la mappa di riferimento. In una fase offline, adattiamo una funzione di interpolazione ed estrapolazione che può regredire il descrittore in una posa invisibile dai descrittori di riferimento noti nei dintorni."
Dopo aver completato questi passaggi, il team ha potuto densificare la mappa considerata dai modelli di VPR aggiungendo i descrittori regrediti per nuove pose, che rappresentano la stessa scena nelle immagini di riferimento, ma leggermente spostati o ruotati. In modo sorprendente, l'approccio ideato da Zaffar e i suoi colleghi non richiede alcuna modifica di progettazione dei modelli di VPR e consente loro di funzionare online, poiché i modelli vengono offerti un set più ampio di riferimenti che possono associare a un'immagine di query. Un ulteriore vantaggio di questo nuovo approccio per VPR è che richiede un minimo di potenza computazionale.
"Altre opere recenti (ad esempio, i campi di radianza neurali e la stereoscopia multi-vista) hanno seguito un pensiero simile, cercando anche di densificare la mappa senza raccogliere più immagini di riferimento", ha detto Zaffar. "Questi lavori hanno proposto di costruire implicitamente/esplicitamente un modello 3D testurizzato dell'ambiente per sintetizzare immagini di riferimento in nuove posizioni e densificare poi la mappa estrarre i descrittori di immagine di queste immagini di riferimento sintetiche. Questo approccio ha parallelismi con le nuvole di punti 3D stimati dalla SLAM visiva, che richiedono una messa a punto accurata e un'ottimizzazione costosa. Inoltre, il descrittore VPR risultante potrebbe essere inclusivo di condizioni di aspetto (clima, stagioni, ecc.) che non sono rilevanti per VPR, o troppo sensibili agli artefatti di ricostruzione accidentali."
Rispetto ai precedenti approcci mirati a migliorare le prestazioni dei modelli di VPR ricostruendo la scena nello spazio dell'immagine, l'approccio di Zaffar esclude questo spazio immagine intermedio, che aumenterebbe il suo carico computazionale e introdurrebbe dettagli irrilevanti. In sostanza, invece di ricostruire queste immagini, l'approccio del team lavora direttamente sui descrittori di riferimento. Ciò rende molto più semplice implementare i modelli di VPR su larga scala.
"Inoltre, il nostro approccio non ha bisogno di avere accesso alle immagini di riferimento stesse, ha solo bisogno dei descrittori di riferimento e delle pose", ha detto Kooij. "Interessantemente, i nostri esperimenti mostrano che l'approccio di regressione dei descrittori è più efficace se un metodo VPR basato su deep learning è stato addestrato con una perdita che pesa le corrispondenze dei descrittori sulla somiglianza di posa, poiché questo aiuta a allineare lo spazio dei descrittori con la geometria delle informazioni visive."
In valutazioni iniziali, il metodo dei ricercatori ha ottenuto risultati molto promettenti, sebbene la semplicità dei modelli impiegati, il che significa che modelli più complessi potrebbero presto ottenere migliori prestazioni. Inoltre, è stato scoperto che il metodo ha un obiettivo molto simile a quello dei metodi esistenti per la stima della posa relativa (cioè per predire come le scene si trasformano quando si guardano da angolazioni specifiche).
"Entrambi gli approcci affrontano diversi tipi di errori di VPR e sono complementari", ha detto Kooij. "La stima della posa relativa può ridurre ulteriormente gli errori di posa finale di un riferimento recuperato correttamente da VPR, ma non può correggere la posa se VPR ha recuperato in modo errato il posto sbagliato con un'apparenza simile al vero luogo ('aliasing percettivo'). Mostriamo con esempi reali che la densificazione della mappa usando il nostro metodo può aiutare a identificare o evitare tali abbinamenti catastrofici."
In the future, the new approach developed by this team of researchers could help to agnostically improve the performance of algorithms for VPR applications, without increasing their computational load. As a result, it could also enhance the overall performance of SLAM or coarse-to-fine-localization systems that rely on these models.
So far, Zaffar and his colleagues have tested their approach using simple regression functions to interpolate and extrapolate descriptors, such as linear interpolation and shallow neural networks, which only considered one or a few nearby reference descriptors. In their next studies, they would like to devise more advanced learning-based interpolation techniques that can consider many more references, as this could improve their approach further.
'For instance, for a query looking down a corridor, a reference further down the corridor could provide more detailed information on what the descriptor should contain than a closer reference looking in the other direction,' Kooij added.
'Another goal for our future work will be to provide a pretrained map densification network that can generalize to different poses on various datasets, and that works well with little to no finetuning. In our current experiments, we fit the model from scratch on a training split of each dataset separately. A unified pretrained model can use more training data, allowing for more complex network architectures, and give better out-of-the-box results to end-users of VPR.'
© 2023 Science X Network



