Une nouvelle approche pour la densification de la carte dans la reconnaissance visuelle des lieux
22 mai 2023 feature
Cet article a été examiné selon le processus éditorial et les politiques de Science X. Les éditeurs ont souligné les attributs suivants tout en garantissant la crédibilité du contenu :
- vérifié par les faits
- publication révisée par des pairs
- source de confiance
- relecture
par Ingrid Fadelli, Tech Xplore
La reconnaissance de lieux visuels (VPR) consiste à identifier l'emplacement où des images spécifiques ont été prises. Les informaticiens ont récemment développé divers algorithmes d'apprentissage en profondeur qui pourraient efficacement résoudre cette tâche, permettant ainsi aux utilisateurs de savoir où dans un environnement connu une image a été capturée.
Une équipe de chercheurs de l'Université de technologie de Delft (TU Delft) a récemment introduit une nouvelle approche pour améliorer les performances des algorithmes d'apprentissage en profondeur pour les applications VPR. Leur méthode proposée, décrite dans un article de IEEE Transactions on Robotics, est basée sur un nouveau modèle appelé régression de descripteur de lieu continu (CoPR).
« Notre étude est issue d'une réflexion sur les goulots d'étranglement fondamentaux dans les performances de VPR, et sur les approches de localisation visuelle associées », a déclaré Mubariz Zaffar, premier auteur de l'étude, à Tech Xplore.
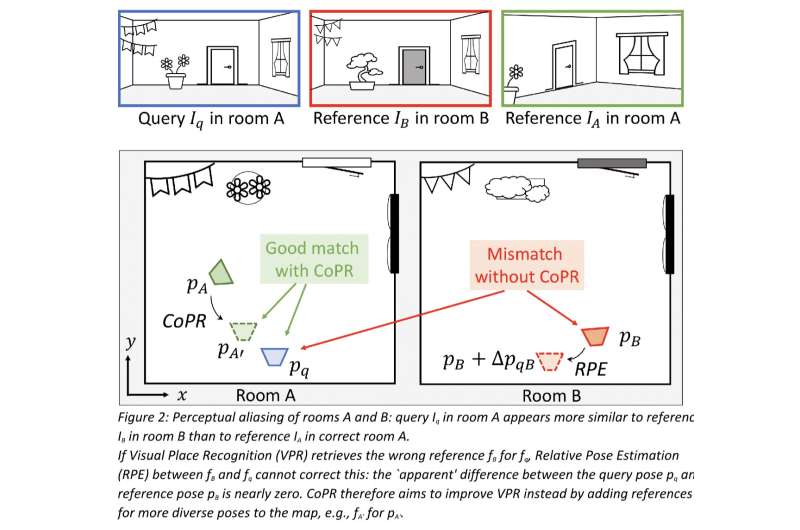
« Tout d'abord, nous avons parlé du problème de 'perceptual aliasing', c'est-à-dire des zones distinctes ayant des apparences visuelles similaires. Comme exemple simple, imaginez que nous collectons des images de référence avec un véhicule roulant sur la voie la plus à droite d'une autoroute. Si nous conduisons plus tard dans la voie la plus à gauche de la même autoroute, l'estimation VPR la plus précise consisterait à faire correspondre ces images de référence proches. Cependant, le contenu visuel pourrait correspondre incorrectement à une section d'autoroute différente où les images de référence ont également été collectées sur la voie la plus à gauche. »
Une façon possible de surmonter cette limitation des approches VPR identifiée par Zaffar et ses collègues pourrait consister à former l'extracteur de descripteur d'image (c'est-à-dire un composant des modèles VPR qui extrait des éléments descriptifs des images) pour analyser les images de manière similaire, indépendamment de la voie de conduite dans laquelle elles sont prises. Cependant, cela réduirait leur capacité à déterminer efficacement l'endroit où une image a été prise.
« Nous nous sommes donc demandés : est-ce que VPR n'est possible que si nous collectons des images sur toutes les voies pour chaque autoroute cartographiée ou si nous ne conduisons que dans la même voie exacte ? Nous voulions étendre le paradigme de récupération d'image simple mais efficace de VPR pour résoudre de tels problèmes pratiques », a déclaré Zaffar.
« Ensuite, nous avons réalisé que même l'estimation de pose d'un système VPR parfait serait limitée en précision, car la taille finie des images de référence et leurs poses signifie que la carte ne peut pas contenir une référence avec la même pose pour chaque requête possible. Nous avons donc considéré qu'il pourrait être plus important de traiter cette clairsemée, plutôt que d'essayer de construire des descripteurs VPR encore meilleurs. »
Lors de l'examen de la littérature précédente, Zaffar et ses collègues ont également réalisé que les modèles VPR sont souvent utilisés dans le cadre d'un système plus vaste. Par exemple, les techniques de cartographie et de localisation simultanées visuelles (SLAM) peuvent bénéficier des approches VPR pour détecter les soi-disant fermetures de boucle, tandis que les approches de localisation grossière à fine peuvent atteindre une précision de localisation submétrique en affinant les estimations de pose grossières de VPR.
« Comparés à ces systèmes plus complexes, l'étape VPR évolue bien dans les environnements larges et est facile à mettre en œuvre, mais son estimation de la pose n'est pas si précise, car elle ne peut renvoyer que les poses des images précédemment vues qui correspondent visuellement le mieux à la requête », a déclaré Zaffar.
« Cependant, SLAM et l'estimation de pose relative fournissent des estimations de pose très précises en utilisant les mêmes images et poses de référence éparses, alors comment ces approches sont-elles fondamentalement différentes de VPR ? Notre observation est que de telles techniques construisent une représentation spatiale continue à partir des références qui relie explicitement une pose aux caractéristiques visuelles, permettant de raisonner sur le contenu visuel à des poses interpolées et extrapolées à partir des références données. »
Sur la base de leurs observations, les chercheurs ont entrepris d'explorer si les mêmes représentations continues atteintes par les approches de SLAM et d'estimation de pose relative pourraient être étendues aux modèles VPR opérant seuls. Les approches VPR conventionnelles fonctionnent en convertissant une image de requête en un vecteur de descripteur unique appelé descripteur, puis en le comparant à des descripteurs précalculés de toutes les images de référence. Collectivement, tous ces descripteurs de référence sont appelés la "carte".
Après avoir comparé ces descripteurs, le modèle détermine quel descripteur de référence correspond le plus étroitement au descripteur de l'image interrogée. Le modèle résout ainsi la tâche de VPR en partageant la position et l'orientation (c'est-à-dire la pose) du descripteur de référence qui est le plus similaire au descripteur de l'image interrogée.
Pour améliorer la localisation de VPR, Zaffar et ses collègues densifient simplement la 'carte' globale des descripteurs en utilisant des modèles d'apprentissage en profondeur. Au lieu de penser aux descripteurs des images de référence comme un ensemble discret séparé de leurs poses, leur méthode considère essentiellement les références comme des points sur une fonction continue sous-jacente qui relie les poses à leur descripteur.
'Si vous pensez à une paire de références avec deux poses proches (donc, des images avec des emplacements et des orientations quelque peu différents, mais regardant toujours la même scène), vous pouvez imaginer que les descripteurs sont quelque peu similaires car ils représentent un contenu visuel similaire,' a expliqué Julian Kooij, co-auteur de l'étude.
'Ils sont toutefois également quelque peu différents car ils représentent des points de vue différents. Alors qu'il serait difficile de définir manuellement comment les descripteurs changent exactement, cela peut être appris à partir des descripteurs de référence sporadiquement disponibles avec es poses connues. C'est alors l'essence de notre approche: nous pouvons modéliser comment les descripteurs d'image changent en fonction d'un changement de pose et l'utiliser pour densifier la carte de référence. À un stade hors ligne, nous adaptons une fonction d'interpolation et d'extrapolation qui peut régresser le descripteur à une pose inconnue à partir des descripteurs de référence connus à proximité.'
Après avoir terminé ces étapes, l'équipe a pu densifier la carte considérée par les modèles de VPR en ajoutant les descripteurs régularisés pour les nouvelles poses, qui représentent la même scène dans les images de référence mais légèrement déplacés ou tournés. De manière remarquable, l'approche conçue par Zaffar et ses collègues ne nécessite aucune modification de conception des modèles de VPR et leur permet de fonctionner en ligne, car les modèles bénéficient d'un ensemble plus large de références auxquelles ils peuvent associer une image interrogée. Un autre avantage de cette nouvelle approche pour VPR est qu'elle nécessite une puissance de calcul relativement minimale.
'Certains autres travaux récents (par exemple, les champs de radiance neurale et la stéréo multi-vue) ont suivi un processus de réflexion similaire, cherchant également à densifier la carte sans collecter plus d'images de référence,' a déclaré Zaffar. 'Ces travaux ont proposé de construire implicitement / explicitement un modèle 3D texturé de l'environnement pour synthétiser des images de référence à de nouvelles poses, puis de densifier la carte en extrayant les descripteurs d'image de ces images de référence synthétiques. Cette approche présente des similitudes avec les nuages de points 3D estimés par SLAM visuel, qui nécessitent un réglage minutieux et une optimisation coûteuse. De plus, le descripteur VPR résultant pourrait être inclusif de conditions d'apparence (météo, saisons, etc.) qui sont considérées comme non pertinentes pour VPR, ou trop sensibles aux artefacts de reconstruction accidentelle.'
Comparé aux approches précédentes visant à améliorer la performance des modèles de VPR en reconstruisant la scène dans l'espace image, l'approche de Zaffar exclut cet espace d'image intermédiaire, ce qui augmenterait sa charge de calcul et introduirait des détails non pertinents. Essentiellement, au lieu de reconstruire ces images, l'approche de l'équipe fonctionne directement sur les descripteurs de référence. Cela rend beaucoup plus facile l'implémentation des modèles de VPR à grande échelle.
'De plus, notre approche n'a pas besoin d'accéder aux images de référence elles-mêmes, elle a simplement besoin des descripteurs et des poses de référence,' a déclaré Kooij. 'De manière intéressante, nos expériences montrent que l'approche de régression des descripteurs est la plus efficace si une méthode VPR basée sur l'apprentissage en profondeur a été formée avec une perte qui pondère les correspondances de descripteurs sur la similarité de poses, car cela aide à aligner l'espace de descripteurs avec la géométrie de l'information visuelle.'
Lors d'évaluations initiales, la méthode des chercheurs a obtenu des résultats très prometteurs malgré la simplicité des modèles utilisés, ce qui signifie que des modèles plus complexes pourraient bientôt améliorer les performances. De plus, il a été constaté que la méthode avait un objectif très similaire à celui des méthodes existantes d'estimation de la pose relative (c'est-à-dire pour prédire comment les scènes se transforment lorsqu'on les regarde depuis des angles spécifiques).
'Les deux approches traitent différents types d'erreurs de VPR et sont complémentaires', a déclaré Kooij. 'L'estimation de la pose relative peut réduire davantage les erreurs de pose finales à partir d'une référence correctement récupérée par VPR, mais elle ne peut pas corriger la pose si VPR a récupéré incorrectement le mauvais endroit avec une apparence similaire à la vraie position ('aliasing perceptif'). Nous montrons avec des exemples du monde réel que la densification de la carte en utilisant notre méthode peut aider à identifier ou à éviter de telles correspondances catastrophiques.'
In the future, the new approach developed by this team of researchers could help to agnostically improve the performance of algorithms for VPR applications, without increasing their computational load. As a result, it could also enhance the overall performance of SLAM or coarse-to-fine-localization systems that rely on these models.
So far, Zaffar and his colleagues have tested their approach using simple regression functions to interpolate and extrapolate descriptors, such as linear interpolation and shallow neural networks, which only considered one or a few nearby reference descriptors. In their next studies, they would like to devise more advanced learning-based interpolation techniques that can consider many more references, as this could improve their approach further.
'For instance, for a query looking down a corridor, a reference further down the corridor could provide more detailed information on what the descriptor should contain than a closer reference looking in the other direction,' Kooij added.
'Another goal for our future work will be to provide a pretrained map densification network that can generalize to different poses on various datasets, and that works well with little to no finetuning. In our current experiments, we fit the model from scratch on a training split of each dataset separately. A unified pretrained model can use more training data, allowing for more complex network architectures, and give better out-of-the-box results to end-users of VPR.'
© 2023 Science X Network



