Ein neuer Ansatz zur Verdichtung von Karten bei der visuellen Ortsbestimmung
22. Mai 2023 Funktion
Dieser Artikel wurde gemäß dem Redaktionsprozess und den Richtlinien von Science X überprüft. Die Herausgeber haben beim Sicherstellen der Glaubwürdigkeit des Inhalts folgende Eigenschaften hervorgehoben:
- Fakt überprüft
- Peer-Review-Veröffentlichung
- Vertrauenswürdige Quelle
- Korrekturgelesen
von Ingrid Fadelli, Tech Xplore
Die visuelle Ortsbestimmung (VPR) ist die Aufgabe, den Ort zu identifizieren, an dem bestimmte Bilder aufgenommen wurden. Kürzlich haben Informatiker verschiedene Deep-Learning-Algorithmen entwickelt, die diese Aufgabe effektiv lösen können. Benutzer können somit erfahren, wo in einer bekannten Umgebung ein Bild aufgenommen wurde.
Ein Team von Forschern der Technischen Universität Delft (TU Delft) hat kürzlich einen neuen Ansatz vorgestellt, um die Leistung von Deep-Learning-Algorithmen für VPR-Anwendungen zu verbessern. Ihre vorgeschlagene Methode, die in einem Artikel in "IEEE Transactions on Robotics" beschrieben wird, basiert auf einem neuen Modell namens kontinuierliche Ortsbeschreibungsregression (CoPR).
"Unsere Studie entstand aus einer Reflexion über die grundlegenden Engpässe in der VPR-Leistung und den damit verbundenen visuellen Lokalisierungsansätzen", sagte Mubariz Zaffar, Erstautor der Studie, zu Tech Xplore.
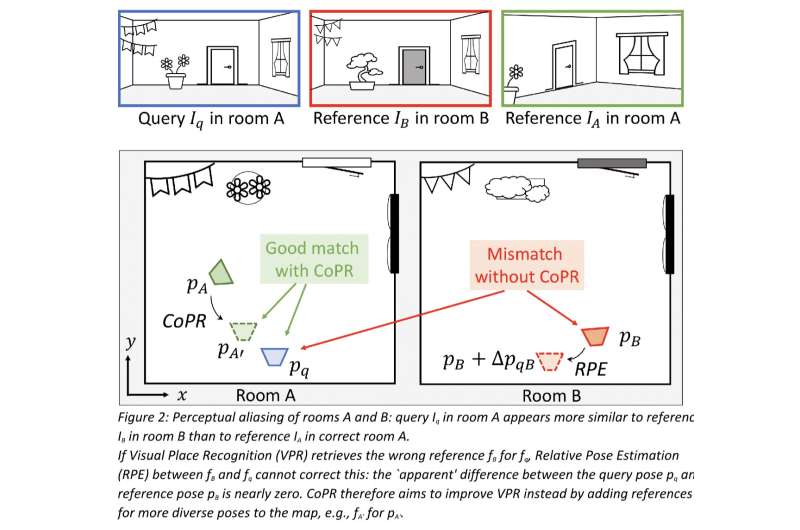
"Zunächst sprachen wir über das Problem der 'Wahrnehmungsverwechslung', d.h. unterschiedliche Bereiche mit ähnlichem visuellem Aussehen. Als einfaches Beispiel stellen Sie sich vor, wir sammeln Referenzbilder mit einem Fahrzeug, das auf der rechten Fahrspur einer Autobahn fährt. Wenn wir später auf der linken Fahrspur derselben Autobahn fahren, wäre die genaueste VPR-Schätzung, diese nahegelegenen Referenzbilder abzugleichen. Der visuelle Inhalt könnte jedoch fälschlicherweise zu einem anderen Autobahnabschnitt passen, wo Referenzbilder auch auf der linken Fahrspur gesammelt wurden."
Eine Möglichkeit, diese von Zaffar und seinen Kollegen identifizierte Einschränkung von VPR-Ansätzen zu überwinden, könnte darin bestehen, dass der sogenannte Bildbeschreibungs-Extraktor (d.h. eine Komponente von VPR-Modellen, die deskriptive Elemente aus Bildern extrahiert) trainiert wird, Bilder unabhängig von der Fahrspur zu analysieren, auf denen sie aufgenommen werden. Dies würde jedoch ihre Fähigkeit reduzieren, den Ort zu bestimmen, an dem ein Bild aufgenommen wurde.
"Wir haben uns also gefragt: Ist VPR nur dann möglich, wenn wir Bilder auf allen Fahrspuren für jede kartierte Autobahn sammeln oder wenn wir nur genau in der gleichen Spur fahren? Wir wollten das einfache, aber effektive Bildrückgewinnungsparadigma von VPR auf diese praktischen Probleme erweitern", sagte Zaffar.
"Zweitens haben wir erkannt, dass selbst die Posen-Schätzung eines perfekten VPR-Systems in der Genauigkeit begrenzt wäre. Die endliche Größe der Referenzbilder und ihrer Posen bedeutet, dass die Karte keine Referenz mit derselben Pose für jede mögliche Abfrage enthalten kann. Wir überlegten daher, dass es wichtiger sein könnte, diese Sparsamkeit anzugehen, anstatt noch bessere VPR-Deskriptoren zu erstellen."
Bei der Überprüfung der bisherigen Literatur erkannten Zaffar und seine Kollegen auch, dass VPR-Modelle oft als Teil eines größeren Systems verwendet werden. Zum Beispiel können visuelle simultane Lokalisierungs- und Kartierungstechniken von VPR-Ansätzen profitieren, um sogenannte Schleifenschlüsse zu erkennen, während grobe bis feine Lokalisierungsansätze eine submetergenaue Lokalisierungsgenauigkeit erreichen können, indem sie die groben Posen-Schätzungen von VPR verfeinern.
"Im Vergleich zu diesen komplexeren Systemen skaliert der VPR-Schritt gut auf große Umgebungen und ist einfach zu implementieren, aber seine Posen-Schätzung ist nicht so genau, da er nur die Posen(s) der zuvor gesehenen Bilder zurückgeben kann, die die Abfrage am besten visuell passen", sagte Zaffar.
"Dennoch bieten SLAM und relative Posen-Schätzung eine hohes Maß an Genauigkeit bei der Posen-Schätzung unter Verwendung der gleichen spärlichen Referenzbilder und Posen, also wie unterscheiden sich diese Ansätze grundlegend von VPR? Unsere Beobachtung ist, dass solche Techniken eine kontinuierliche räumliche Darstellung aus den Referenzen aufgebaut haben, die eine Pose mit den visuellen Merkmalen explizit in Beziehung setzt und es ermöglicht, über den visuellen Inhalt an Posen interpoliert und extrapoliert aus den gegebenen Referenzen nachzudenken."
Auf der Grundlage ihrer Beobachtungen machten sich die Forscher daran, zu untersuchen, ob die gleichen kontinuierlichen Darstellungen, die von SLAM- und relativen Posen-Schätzungsansätzen erreicht werden, auf VPR-Modelle, die allein arbeiten, erweitert werden können. Herkömmliche VPR-Ansätze arbeiten damit, dass ein Abfragebild in einen einzigen sogenannten Deskriptorvektor umgewandelt wird und dann mit vorberechneten Deskriptoren aller Referenzen verglichen wird. Alle diese Referenzdeskriptoren werden gemeinsam als "Karte" bezeichnet.
Nachdem diese Deskriptoren verglichen wurden, bestimmt das Modell, welcher Referenz-Deskriptor am besten zum Deskriptor des Suchbildes passt. Das Modell löst somit die VPR-Aufgabe, indem es den Ort und die Ausrichtung (d.h. die Pose) des Referenz-Deskriptors teilt, der dem Deskriptor des Suchbildes am ähnlichsten ist.
Um die VPR-Ortung zu verbessern, verdichtet Zaffar mit seinen Kollegen einfach die gesamte "Landkarte" der Deskriptoren, indem er Deep-Learning-Modelle einsetzt. Statt die Deskriptoren von Referenzbildern als diskrete Menge zu betrachten, die von ihren Posen getrennt ist, betrachtet ihre Methode die Referenzen im Wesentlichen als Punkte auf einer zugrunde liegenden kontinuierlichen Funktion, die Posen mit ihren Deskriptoren verbindet.
"Wenn man sich ein Paar von Referenzen mit zwei nahe gelegenen Posen vorstellt (d.h. Bilder mit etwas unterschiedlichen Orten und Ausrichtungen, aber immer noch mit Blick auf die gleiche Szene), kann man sich vorstellen, dass die Deskriptoren etwas ähnlich sind, da sie ähnliche visuelle Inhalte repräsentieren", erklärt Julian Kooij, Mitautor der Studie. "Dennoch sind sie auch etwas unterschiedlich, da sie unterschiedliche Perspektiven repräsentieren. Während es schwer wäre, genau zu definieren, wie sich die Deskriptoren ändern, kann dies aus den unregelmäßig verfügbaren Referenz-Deskriptoren mit bekannten Posen gelernt werden. Das ist dann die Essenz unseres Ansatzes: Wir können modeln, wie sich Bild-Deskriptoren als Funktion einer Änderung der Pose ändern, und dies verwenden, um die Referenzkarte zu verdichten. In einem Offline-Stadium passen wir eine Interpolations- und Extrapolationsfunktion an, die den Deskriptor bei einer neuen Pose aus den nahe gelegenen bekannten Referenz-Deskriptoren regressieren kann."
Nach Abschluss dieser Schritte konnte das Team die von VPR-Modellen betrachtete Karte verdichten, indem sie die regressierten Deskriptoren für neue Posen hinzufügen, die dieselbe Szene in den Referenzbildern darstellen, aber leicht verschoben oder gedreht sind. Bemerkenswerterweise erfordert der von Zaffar und seinen Kollegen entwickelte Ansatz keine Designänderungen an VPR-Modellen und ermöglicht es ihnen, online zu arbeiten, da den Modellen eine größere Menge an Referenzen zur Verfügung steht, die sie einem Suchbild zuordnen können. Ein weiterer Vorteil dieses neuen Ansatzes für VPR besteht darin, dass er relativ geringe Rechenleistung erfordert.
"Einige andere jüngste Arbeiten (z. B. neuronale Radiance-Felder und Multi-View Stereo) folgten einem ähnlichen Gedankengang und versuchten ebenfalls, die Karte ohne Sammeln von mehr Referenzbildern zu verdichten", sagte Zaffar. "Diese Arbeiten schlugen vor, implizit/explicit einen texturierten 3D-Modell der Umgebung zu erstellen, um Referenzbilder bei neuen Posen zu synthetisieren, und dann die Karte zu verdichten, indem man die Bild-Deskriptoren dieser synthetischen Referenzbilder extrahiert. Dieser Ansatz hat Parallelen zu den 3D-Punktewolken, die von visuellem SLAM geschätzt werden, und er erfordert eine sorgfältige Abstimmung und teure Optimierung. Außerdem könnte der resultierende VPR-Deskriptor Bedingungen des Erscheinungsbilds (Wetter, Jahreszeiten usw.) einschließen, die für VPR irrelevant sind, oder überempfindlich gegenüber unbeabsichtigten Rekonstruktionsartefakten sein."
Verglichen mit früheren Ansätzen, die darauf abzielen, die Leistung von VPR-Modellen durch Rekonstruktion des Szenenraums im Bildraum zu verbessern, schließt Zaffars Ansatz diesen Zwischenbildraum aus, der seine Rechenlast erhöhen und irrelevante Details einführen würde. Im Wesentlichen arbeitet der Ansatz des Teams an den Referenz-Deskriptoren, anstatt diese Bilder wieder aufzubauen. Dies macht es wesentlich einfacher, VPR-Modelle im großen Maßstab umzusetzen.
"Außerdem benötigt unser Ansatz keinen Zugriff auf die Referenzbilder selbst, er benötigt nur die Referenz-Deskriptoren und Posen", sagte Kooij. "Interessanterweise zeigen unsere Experimente, dass der Deskriptor-Regressionsansatz am effektivsten ist, wenn eine VPR-Methode auf Basis von Deep Learning mit einem Verlust trainiert wurde, der Deskriptor-Übereinstimmungen auf die Ähnlichkeit der Pose gewichtet, da dies hilft, den Deskriptorraum mit der Geometrie visueller Informationen auszurichten."
In ersten Evaluierungen erzielte die Methode der Forscher sehr vielversprechende Ergebnisse, obwohl die verwendeten Modelle einfach sind, was bedeutet, dass komplexere Modelle bald eine bessere Leistung erzielen könnten. Außerdem stellte sich heraus, dass die Methode ein sehr ähnliches Ziel hat wie bestehende Methoden für die relative Pose-Schätzung (d.h. für die Vorhersage, wie sich Szenen verändern, wenn man sie aus bestimmten Winkeln betrachtet).
"Beide Ansätze adressieren verschiedene Arten von VPR-Fehlern und ergänzen sich", sagte Kooij. "Relative Pose-Schätzung kann die finalen Pose-Fehler von einem korrekt abgerufenen Referenzpunkt durch VPR weiter reduzieren, aber sie kann die Pose nicht korrigieren, wenn VPR den falschen Ort mit einem ähnlichen Aussehen wie dem wahren Ort ('perzeptive Fehlzuordnung') fälschlicherweise abruft. Wir zeigen anhand realer Beispiele, dass die Kartenverdichtung mit unserer Methode helfen kann, solche katastrophalen Missanpassungen zu identifizieren oder zu vermeiden."
In the future, the new approach developed by this team of researchers could help to agnostically improve the performance of algorithms for VPR applications, without increasing their computational load. As a result, it could also enhance the overall performance of SLAM or coarse-to-fine-localization systems that rely on these models.
So far, Zaffar and his colleagues have tested their approach using simple regression functions to interpolate and extrapolate descriptors, such as linear interpolation and shallow neural networks, which only considered one or a few nearby reference descriptors. In their next studies, they would like to devise more advanced learning-based interpolation techniques that can consider many more references, as this could improve their approach further.
'For instance, for a query looking down a corridor, a reference further down the corridor could provide more detailed information on what the descriptor should contain than a closer reference looking in the other direction,' Kooij added.
'Another goal for our future work will be to provide a pretrained map densification network that can generalize to different poses on various datasets, and that works well with little to no finetuning. In our current experiments, we fit the model from scratch on a training split of each dataset separately. A unified pretrained model can use more training data, allowing for more complex network architectures, and give better out-of-the-box results to end-users of VPR.'
© 2023 Science X Network



