Un nuevo enfoque para la densificación de mapas en el reconocimiento visual de lugares.
22 de mayo de 2023 función
Este artículo ha sido revisado de acuerdo con el proceso editorial y las políticas de Science X. Los editores han destacado los siguientes atributos mientras garantizan la credibilidad del contenido:
- verificación de hechos
- publicación revisada por pares
- fuentes confiables
- corrección de pruebas
por Ingrid Fadelli, Tech Xplore
El reconocimiento visual de lugares (VPR) es la tarea de identificar el lugar donde se tomaron imágenes específicas. Los científicos informáticos han desarrollado recientemente diversos algoritmos de aprendizaje profundo que podrían abordar eficazmente esta tarea, permitiendo a los usuarios saber dónde se capturó una imagen dentro de un ambiente conocido.
Un equipo de investigadores de la Universidad de Tecnología de Delft (TU Delft) presentó recientemente un nuevo enfoque para mejorar el rendimiento de los algoritmos de aprendizaje profundo para aplicaciones VPR. Su método propuesto, descrito en un artículo en IEEE Transactions on Robotics, se basa en un nuevo modelo llamado regresión continua de descriptores de lugar (CoPR).
"Nuestro estudio se originó a partir de una reflexión sobre los cuellos de botella fundamentales en el rendimiento de VPR y en los enfoques de localización visual relacionados", dijo Mubariz Zaffar, primer autor del estudio, a Tech Xplore.
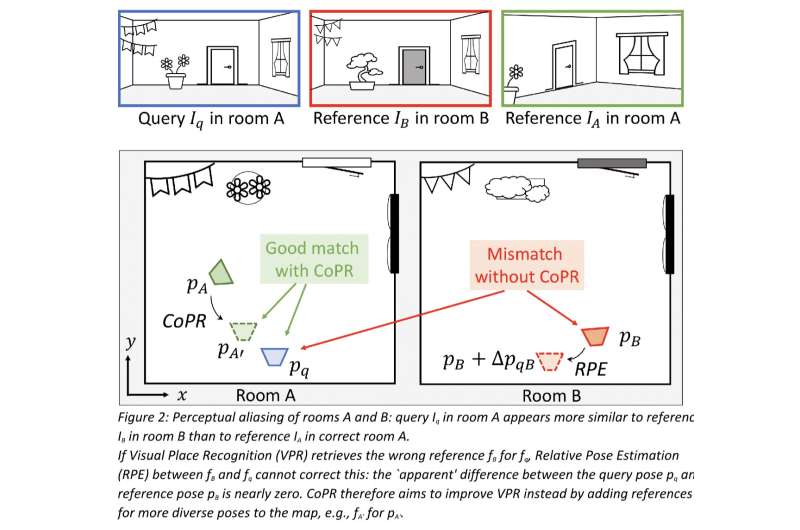
"En primer lugar, hablamos del problema del 'aliasing perceptual', es decir, áreas distintas con apariencias visuales similares. Como ejemplo simple, imagina que recopilamos imágenes de referencia con un vehículo que conduce en el carril más a la derecha de una autopista. Si más tarde conducimos en el carril más a la izquierda de la misma autopista, la estimación de VPR más precisa sería relacionar estas imágenes de referencia cercanas. Sin embargo, el contenido visual podría coincidir incorrectamente con una sección de la autopista diferente donde también se recopilaron imágenes de referencia en el carril más a la izquierda".
Una posible forma de superar esta limitación de los enfoques de VPR identificados por Zaffar y sus colegas podría ser entrenar al llamado extractor de descriptores de imagen (es decir, un componente de los modelos de VPR que extrae elementos descriptivos de las imágenes) para analizar las imágenes de manera similar sin importar el carril de conducción en el que se tomen. Sin embargo, esto reduciría su capacidad para determinar eficazmente el lugar donde se tomó una imagen.
"Por lo tanto, nos preguntamos: ¿es VPR solo posible si recopilamos imágenes en todos los carriles para cada autopista mapeada o si solo conducimos en el mismo carril exacto? Queríamos extender el paradigma de recuperación de imagen simple pero efectivo de VPR para manejar estos problemas prácticos", dijo Zaffar.
"En segundo lugar, nos dimos cuenta de que incluso la estimación de la pose de un sistema VPR perfecto estaría limitada en precisión, ya que el tamaño finito de las imágenes de referencia y sus poses significa que el mapa no puede contener una referencia con la misma pose exacta para cada posible consulta. Por lo tanto, consideramos que puede ser más importante abordar esta escasez en lugar de tratar de construir descriptores de VPR aún mejores".
Cuando revisaron la literatura anterior, Zaffar y sus colegas también se dieron cuenta de que los modelos de VPR se usan a menudo como parte de un sistema más grande. Por ejemplo, las técnicas visuales de localización y mapeo simultáneos (SLAM) pueden beneficiarse de los enfoques de VPR para detectar los llamados cierres de bucle, mientras que los enfoques de localización de grueso a fino pueden lograr una precisión de localización submétrica refinando las estimaciones de la pose gruesa de VPR.
"En comparación con estos sistemas más complejos, el paso de VPR se escala bien a los entornos grandes y es fácil de implementar, pero su estimación de la pose no es tan precisa, ya que solo puede devolver la pose(s) de la(s) imagen(es) vista(s) anteriormente que mejor coinciden visualmente con la consulta", dijo Zaffar.
"Sin embargo, SLAM y la estimación de la pose relativa proporcionan estimaciones de pose muy precisas utilizando las mismas imágenes de referencia y poses dispersas, entonces, ¿cómo son fundamentalmente diferentes estos enfoques de VPR? Nuestra observación es que estas técnicas construyen una representación espacial continua a partir de las referencias que relaciona explícitamente una pose con las características visuales, lo que permite razonar sobre el contenido visual en poses interpoladas y extrapoladas a partir de las referencias dadas".
Basándose en sus observaciones, los investigadores se propusieron explorar si las mismas representaciones continuas alcanzadas por los enfoques de SLAM y estimación de pose relativa podrían extenderse a modelos de VPR que operan solos. Los enfoques convencionales de VPR trabajan convirtiendo una imagen de consulta en un solo vector de descriptor y luego comparándolo con los descriptores precalculados de todas las imágenes de referencia; colectivamente, todos estos descriptores de referencia se denominan "mapa".
Después de comparar estos descriptores, el modelo determina qué descriptor de referencia se ajusta más al descriptor de la imagen de la consulta. Así, el modelo resuelve la tarea de VPR compartiendo la ubicación y orientación (es decir, posesión) del descriptor de referencia que se parece más al descriptor de la imagen de la consulta.
Para mejorar la localización de VPR, Zaffar y sus colegas simplemente densificaron el "mapa" general de los descriptores empleando modelos de aprendizaje profundo. En lugar de pensar en los descriptores de las imágenes de referencia como un conjunto discreto separado de sus posesos, su método considera esencialmente las referencias como puntos en una función continua subyacente que relaciona las poses con sus descriptores.
"Si piensas en un par de referencias con dos poses cercanas (por lo tanto, imágenes con ubicaciones y orientaciones algo diferentes, pero aún mirando la misma escena), puedes imaginar que los descriptores son algo similares ya que representan contenido visual similar", explicó Julian Kooij, co-autor del estudio. "Aún así, también son algo diferentes ya que representan puntos de vista diferentes. Mientras que sería difícil definir manualmente cómo cambian exactamente los descriptores, esto se puede aprender de los descriptores de referencia escasamente disponibles con poseses conocidas. Esto es esencialmente la esencia de nuestro enfoque: podemos modelar cómo cambian los descriptores de las imágenes como una función de un cambio en la pose y usar esto para densificar el mapa de referencia. En una etapa fuera de línea, ajustamos una función de interpolación y extrapolación que puede regresar el descriptor en una pose no vista a partir de los descriptores de referencia cercanos conocidos."
Después de completar estos pasos, el equipo pudo densificar el mapa considerado por los modelos de VPR agregando los descriptores regresados para nuevas posesos, que representan la misma escena en las imágenes de referencia pero ligeramente movidas o rotadas. Sorprendentemente, el enfoque ideado por Zaffar y sus colegas no requiere ninguna alteración del diseño para los modelos de VPR y les permite operar en línea, ya que los modelos se les ofrece un conjunto más grande de referencias con las que pueden hacer coincidir una imagen de consulta. Una ventaja adicional de este nuevo enfoque para VPR es que requiere una potencia de cálculo relativamente mínima.
"Algunos otros trabajos recientes (por ejemplo, campos de radiación neural y estéreo de múltiples vistas) siguieron un proceso de pensamiento similar, también buscando densificar el mapa sin recopilar más imágenes de referencia", dijo Zaffar. "Estos trabajos propusieron construir implícita/explicitamente un modelo 3D texturizado del entorno para sintetizar imágenes de referencia en nuevas poses, y luego densificar el mapa extrayendo los descriptores de imagen de estas imágenes de referencia sintéticas. Este enfoque tiene paralelos con las nubes de puntos 3D estimadas por Visual SLAM, y que requiere una optimización cuidadosa y costosa. Además, el descriptor VPR resultante podría ser inclusivo de condiciones de apariencia (clima, temporadas, etc.), que se consideran irrelevantes para VPR, o demasiado sensibles a artefactos de reconstrucción accidentales".
En comparación con enfoques anteriores destinados a mejorar el rendimiento de los modelos de VPR reconstruyendo la escena en el espacio de la imagen, el enfoque de Zaffar excluye este espacio de imagen intermedia, que aumentaría su carga computacional e introduciría detalles irrelevantes. Esencialmente, en lugar de reconstruir estas imágenes, el enfoque del equipo trabaja directamente en los descriptores de referencia. Esto hace que sea mucho más fácil de implementar en modelos de VPR a gran escala.
"Además, nuestro enfoque no necesita tener acceso a las imágenes de referencia en sí mismas, solo necesita los descriptores de referencia y las poseses", dijo Kooij. "Curiosamente, nuestros experimentos muestran que el enfoque de regresión de descriptores es más efectivo si un método VPR basado en el aprendizaje profundo se entrenó con una pérdida que pese las coincidencias de descriptores en la similitud de poses, ya que esto ayuda a alinear el espacio de descriptores con la geometría de la información visual."
En evaluaciones iniciales, el método de los investigadores logró resultados muy prometedores, aunque la simplicidad de los modelos empleados, lo que significa que modelos más complejos podrían lograr mejores resultados. Además, se encontró que el método tenía un objetivo muy similar al de los métodos existentes para la estimación de poses relativas (es decir, para predecir cómo se transforman las escenas cuando se las mira desde ángulos específicos).
"Ambos enfoques abordan diferentes tipos de errores de VPR y son complementarios", dijo Kooij. "La estimación de poses relativas puede reducir aún más los errores de poses finales de una referencia recuperada correctamente por VPR, pero no puede corregir a VPR si ha recuperado incorrectamente el lugar equivocado con una apariencia similar a la ubicación real ('aliasing perceptual'). Mostramos con ejemplos del mundo real que la densificación del mapa utilizando nuestro método puede ayudar a identificar o evitar tales desajustes catastróficos".
In the future, the new approach developed by this team of researchers could help to agnostically improve the performance of algorithms for VPR applications, without increasing their computational load. As a result, it could also enhance the overall performance of SLAM or coarse-to-fine-localization systems that rely on these models.
So far, Zaffar and his colleagues have tested their approach using simple regression functions to interpolate and extrapolate descriptors, such as linear interpolation and shallow neural networks, which only considered one or a few nearby reference descriptors. In their next studies, they would like to devise more advanced learning-based interpolation techniques that can consider many more references, as this could improve their approach further.
'For instance, for a query looking down a corridor, a reference further down the corridor could provide more detailed information on what the descriptor should contain than a closer reference looking in the other direction,' Kooij added.
'Another goal for our future work will be to provide a pretrained map densification network that can generalize to different poses on various datasets, and that works well with little to no finetuning. In our current experiments, we fit the model from scratch on a training split of each dataset separately. A unified pretrained model can use more training data, allowing for more complex network architectures, and give better out-of-the-box results to end-users of VPR.'
© 2023 Science X Network



